

Quiz #20 was:
You are a DevOps engineer responsible for managing a Kubernetes cluster. Recently, you noticed a significant number of pods going up and down unexpectedly, causing instability in your applications. After some investigation, you traced the issue to a recent change in a Custom Resource Definition (CRD) related to your cluster’s autoscaling. What might be the root cause of this problem?
1. Incorrect resource requests and limits set for the pods
2. A CRD change in Karpenter causing it to add/delete nodes rapidly (Correct Answer)
3. Network congestion affecting pod communication
4. Pod anti-affinity rules misconfiguration
5. Kubernetes API server overload due to excessive requests
Correct Answer: 2) A CRD change in Karpenter causing it to add/delete nodes rapidly
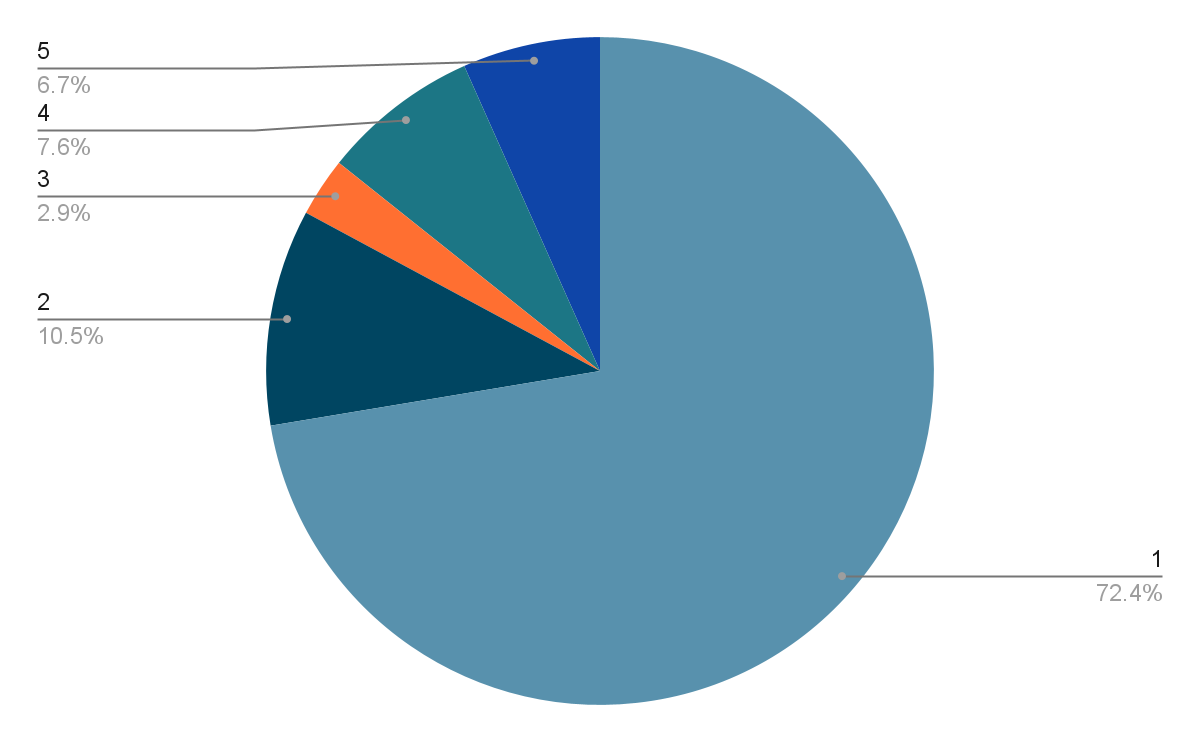
105 people answered this question and only 11% got it right.
In the world of Kubernetes, maintaining the stability and reliability of your applications is a top priority for DevOps and SRE teams. However, when you encounter a situation where a significant number of pods start going up and down unexpectedly, it can be a challenging puzzle to solve. In this blog, we’ll dive into a real-world scenario where such issues occurred and explore why a recent change in a Custom Resource Definition (CRD) related to Karpenter’s autoscaling was the root cause, while other common issues were not.
The Scenario
Imagine you’re responsible for managing a Kubernetes cluster that has been running smoothly for a while. Suddenly, you start receiving alerts and notices about pods experiencing frequent disruptions. This instability not only affects the reliability of your applications but also puts your team on high alert. It’s time to investigate and identify the root cause.
The Choices
To troubleshoot this issue, you consider various possibilities. Here are the options you evaluate:
1. Incorrect resource requests and limits set for the pods: This is a common consideration when pods are unstable. However, after reviewing the pod configurations, you find that resource requests and limits are well-defined and appropriate.
2. Network congestion affecting pod communication: Network issues can certainly lead to unstable pods. You check network metrics and configurations, but everything appears to be functioning normally.
3. A CRD change in Karpenter causing it to add/delete nodes rapidly (Correct Answer): This choice catches your attention because it directly relates to the cluster’s autoscaling behavior. You investigate further and discover that a recent change in a CRD associated with Karpenter’s autoscaling caused it to add and delete nodes rapidly, impacting pod stability.
4. Pod anti-affinity rules misconfiguration: Pod anti-affinity rules can influence pod placement and stability. However, upon reviewing the configurations, you find no misconfigurations related to anti-affinity rules.
5. Kubernetes API server overload due to excessive requests: API server overload can lead to delayed responses and pod disruptions. However, after monitoring API server metrics, you conclude that it is not the primary cause of the unstable pods.
The Explanation
The correct answer is #3: A CRD change in Karpenter causing it to add/delete nodes rapidly. In this scenario, Karpenter, a component responsible for autoscaling your cluster, underwent a CRD change that unintentionally triggered rapid node additions and deletions. This directly impacted the stability of your pods because they were constantly rescheduled to different nodes, leading to disruptions.
While other factors like resource configurations and network issues are valid concerns, it’s essential to methodically investigate each possibility. In this case, understanding the recent CRD changes and their implications for cluster behavior was the key to resolving the issue.
Conclusion
When faced with unstable pods in your Kubernetes cluster, thorough investigation and systematic troubleshooting are essential. In this scenario, a CRD change in Karpenter proved to be the root cause, highlighting the importance of monitoring and understanding changes to critical components.
By staying vigilant, regularly reviewing changes, and considering all possible factors, DevOps and SRE teams can maintain the stability and reliability of their Kubernetes-based applications, ensuring uninterrupted service for users.
Ready to enhance your Kubernetes troubleshooting skills further? Read our blog on the importance of CRDs.
Don’t waste precious time manually troubleshooting such failures. Leverage AI to automate troubleshooting reducing downtime and toil – see how by signing up for our Early Access Program.